Compliance made easy with a single capture, archive, supervision and discovery platform
Simplified communications compliance for communications supervision — from single offices to the world’s largest enterprises.
Smarsh is the global leader in digital communications capture, archiving and oversight
For more than 20 years, we have served organizations in the most regulated sectors, including global and regional financial services firms and government agencies. We set the standard for communications compliance — and we continue to raise it higher.

%
top financial firms trust Smarsh

Million +
Microsoft Teams users captured

of messages managed monthly
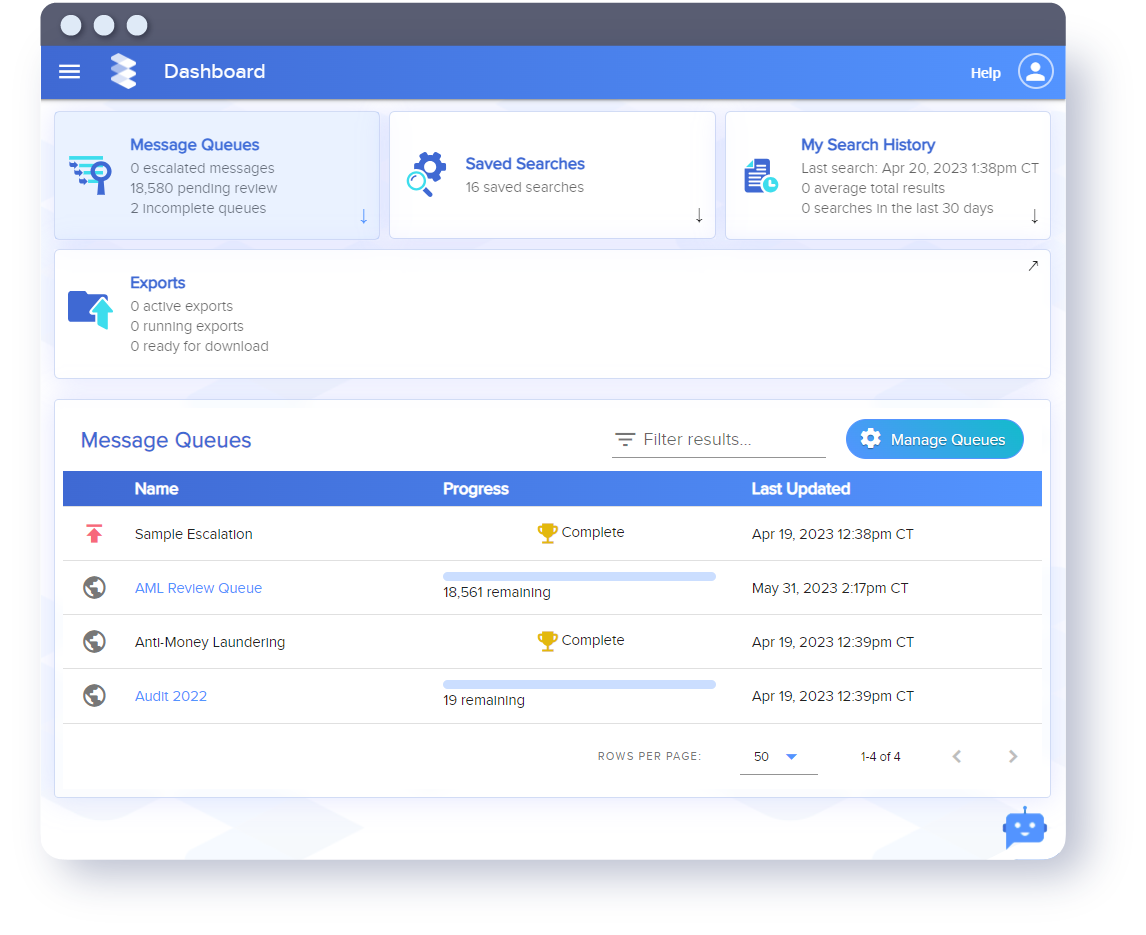
CAPTURE
More channels, more data, more risk
Collaboration across fast-paced, distributed teams means new channels, more data and more risk than ever before. Capture all your communications in one place.
ARCHIVE
Purpose-built solutions designed for today
Other archives weren’t meant to handle today's variety of communications tools. Ours were built for it. Securely preserve data and harness it for your critical business insights.
DISCOVERY
Search e-communications data in record time
Facing litigation, early case assessment or investigation? Search e-communications data and produce reports in real time with Smarsh discovery tools.
SUPERVISION
Spot risks before they become fines and headlines
Smarsh helps you proactively spot and quickly review red flags in your employee communications to prevent risk more effectively.
SURVEILLANCE
Safeguard performance, reputation, and culture
Elevate your supervisory requirements to monitor employee conduct, intents and actions. Using battle-tested artificial intelligence, machine learning and natural language processing, Smarsh helps spot undesirable behaviors before they create detrimental outcomes.
A $2.8 Billion Problem
One Solution
Financial services organizations have been put on notice about off-channel communications as fines for violations continue to soar. With so many ways to collaborate, it's easy to see how it's become a $2.8 problem. Fortunately, it only takes one solution – Smarsh – to enable your teams to collaborate compliantly and turn off-channel on.


What’s New at Smarsh
Smarsh Acquires TeleMessage
TeleMessage joins Smarsh for the most comprehensive mobile compliance solution for preventing off-channel fines.
Have Questions About Off-Channel Communications?
Get expert insights and emerging best practices to stay ahead of compliance.
Smarsh Named Top Player in 2024 Radicati Quadrant
Learn why Smarsh was named a Top Player for the fourteenth year in a row
Yet again!
Smarsh named to Inc. 5000 list for 16th straight year

Smarsh named a TOP PLAYER for the 14th year
2024
Radicati
Market Quadrant
for Information Archiving
THE FUTURE OF COMMUNICATIONS
CAPTURE AND ARCHIVING IS HERE.